What is a Compiler? How Does It Work? (An Easy Explanation)

Introduction
A computer’s CPU, which is responsible for running your code, doesn’t understand JavaScript, Go, C++ or any other high-level programming languages that we know. These high-level languages, are basically some layers of abstraction, made by computer programmers and engineers, so speaking to a computer becomes easier for us as humans.
What is a Compiler?
A CPU, and computer’s hardware in general, only understand zeros and ones, which we technically refer to as binary code. The reason behind this is that a computer’s hardware is basically made out of billions of transistors, which can only have two states: on or off. These “on” and “off” states are represented with zeros and ones; 1 meaning on, thus the electrons pass through, and 0 meaning off, which stops electricity from passing through a transistor. Literally everything that a computer does, is made possible by these on or off states of those tiny transistors.
Now, compilers are fascinating tools that transform the high-level code written by programmers, which is more easily readable by humans compared to zeros and ones, into binary code language that computers understand.
At its core, a compiler is like a translator. Just as a person might translate Spanish into English, a compiler translates the code written in a high-level programming language, into machine code (binary code).
But How Do Compilers Work?
The process of compilation, which is the name of what a compiler does under the hood, involves several stages. Here we take a brief look at each of these stages, all with real examples:
1. Lexical Analysis: This is the first step where the compiler breaks down the code into basic elements or tokens. For example, in the line String greeting = "Hello";, the tokens would be String, greeting, =, "Hello", and ;.

2. Syntax Analysis: Here, the compiler uses the tokens to build a structure called an Abstract Syntax Tree (AST), which represents the logical structure of the program. This step checks the grammatical structure of the code and looks for syntax errors. If an AST’s structure becomes invalid, the compiler immediately knows that the original code had a syntax error, and in most cases it knows exactly where the error is coming from.

3. Semantic Analysis: The compiler uses the AST to detect semantic errors, such as assigning the wrong type to a variable or using a keyword as a variable name. This stage includes type checking, flow control checking, and label checking.

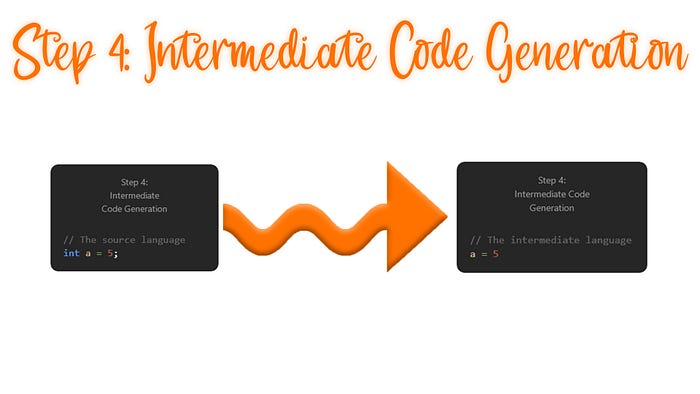
4. Intermediate Code Generation: The compiler generates an intermediate code that is machine-independent; meaning that it can be used on any hardware later on to generate the final binary code for that specific machine. This also means that the code can be easily translated into the machine code of any target machine. The intermediate code can be either high-level, similar to the source language, or low-level, closer to machine code. Now you might ask, if the generated intermediate language may be sometimes similar to the source code or another high-level language, what is the need for generating it at all? Can’t we just make the original source code machine-independent? The answer is pretty easy: The compiler does that so it can optimize the code way more easily, make sure that the code has the least amount of dependencies to your current hardware, and the complexity of designing a compiler decreases.
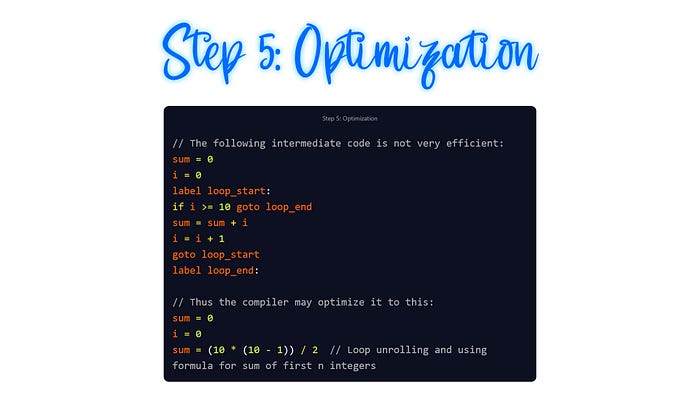
5. Optimization: In this phase, the compiler makes the code more efficient without altering its meaning and purpose. The optimization focuses on consuming fewer resources and speeding up the operation of the software. This is where the intermediate language that was generated in the previous step becomes really handy! In the upcoming example, the original source code written in C was this:

Then it was used to generate the intermediate code, which consists of a highly inefficient loop, and then was optimized by the compiler to eliminate the problematic part:
6. Code Generation: Finally, the compiler converts the optimized intermediate code into the machine code specific to the target machine. This code should be efficient in terms of memory and CPU resource usage. This is actually where the compiler does its magic! It knows if your CPU understands Spanish Binary (which is a word that I just made up to make it easier to understand) or English Binary. Our Mr. Translator knows exactly what each of those words of the intermediate language mean in the binary language of your own CPU. How? By examining and using the actual hardware that you’re using, and sometimes some of the high-level APIs that are accessible from the operating system itself.

Advanced Resources
The overall process of a compiler design isn’t really hard to understand. But if you want to get deep and actually design a compiler yourself or even contribute to an already-existing compiler, you definitely need more advanced knowledge about each steps. Here, I include some resources that I think they may be helpful for the advanced readers. I haven’t studied all of them myself, so please do your own research before actually studying any of them:
- Compilers: Principles, Techniques, and Tools” by Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman, often referred to as the “Dragon Book”.
- “Engineering a Compiler” by Keith Cooper and Linda Torczon.
- Online courses on platforms like Coursera, edX, and MIT OpenCourseWare, which often feature in-depth lectures and materials on compiler design.
If you’re really into designing a compiler, I suggest you start with reading the code of open-source compilers. This gives you a clear vision of what is exactly going on under the hood. Also by contributing to these open-source compilers, you’re not only helping yourself learn more by getting your hands dirty, but also helping a lot of people out there who are actually using those tools! That’s how we, as software engineers, have each other’s backs. :)
